Overview
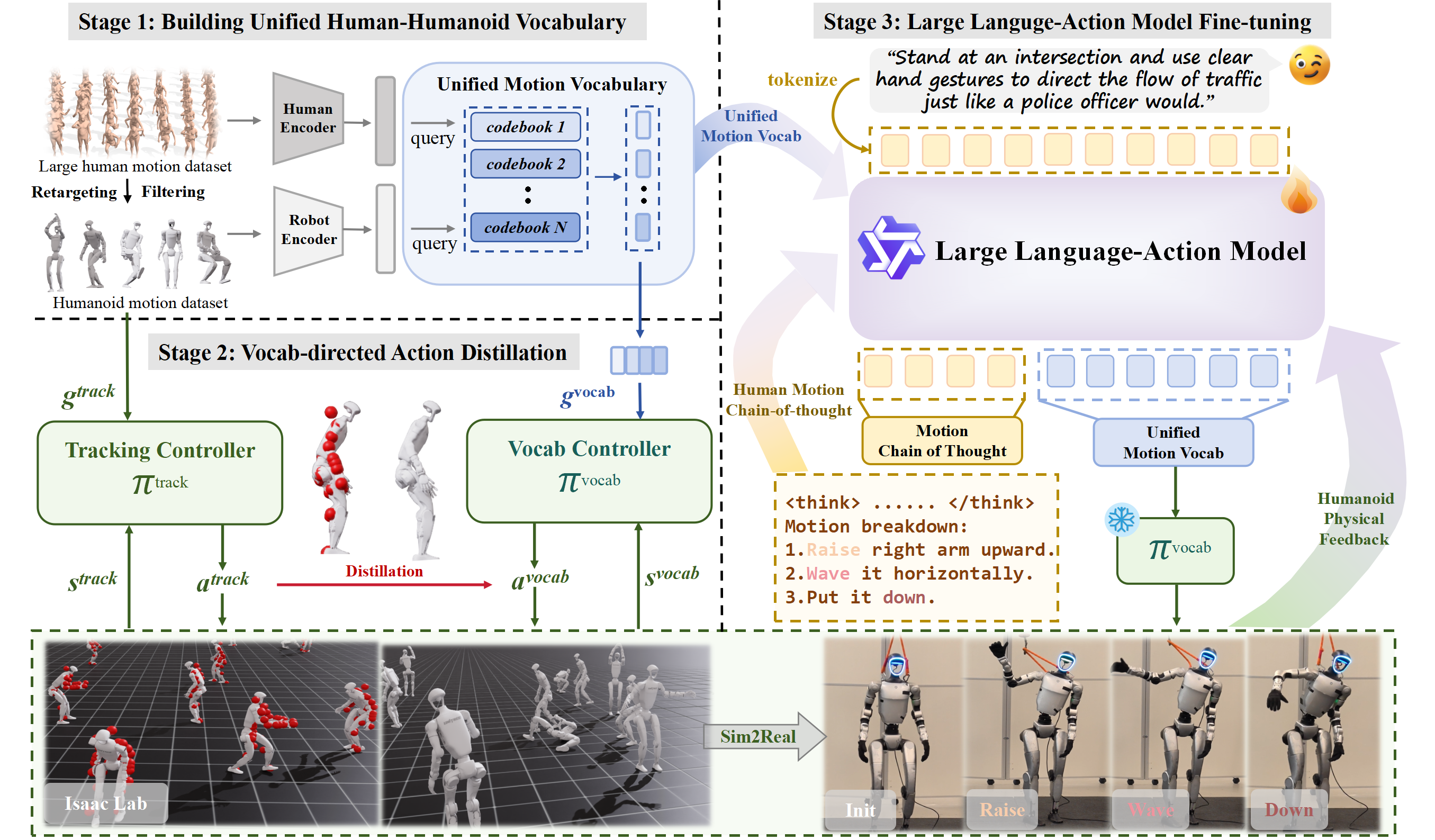
Enabling humanoid robots to follow free-form language commands is critical for seamless human-robot interaction, collaborative task execution, and general-purpose embodied intelligence. While recent advances have improved low-level humanoid locomotion and robot manipulation, language-conditioned whole-body control remains a significant challenge. Existing methods are often limited to simple instructions and sacrifice either motion diversity or physical plausibility. To address this, we introduce Humanoid-LLA, a Large Language Action Model that maps expressive language commands to physically executable whole-body actions for humanoid robots. Our approach integrates three core components: a unified motion vocabulary that aligns human and humanoid motion primitives into a shared discrete space; a vocabulary-directed controller distilled from a privileged policy to ensure physical feasibility; and a physics-informed fine-tuning stage using reinforcement learning with dynamics-aware rewards to enhance robustness and stability. Extensive evaluations in simulation and on a real-world Unitree G1 humanoid show that Humanoid-LLA delivers strong language generalization while maintaining high physical fidelity, outperforming existing language-conditioned controllers in motion naturalness, stability, and execution success rate.
Walk with a confident and happy strut.
A zombie is coming.
A person is playing golf.
Prompt Direct traffic like a policeman.
LangWBC
Ours
Prompt A joyful dance with beated hip-hop.
LangWBC
Ours
A teacher is giving a lecture.
A gardener is watering flowers.
@article{liu2025commanding,
title={Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion Vocabulary},
author={Liu, Zhirui and Ji, Kaiyang and Yang, Ke and Yu, Jingyi and Shi, Ye and Wang, Jingya},
journal={arXiv preprint arXiv:2511.22963},
year={2025}
}